AX1554
Using iterative task processing
You can configure a Scheduler task to use iterative processing, so that the task is repeated multiple times using a designated list of values. Each iteration of the task uses a different item in the list, until all items have been processed.
When you enable iterative processing for a task, you define the list of values by specifying a table column and an optional filter. The task will then be processed for each unique item in the table column. You can reference the column values within the task properties by using a built-in Scheduler job variable. As each iteration of the task is processed, the variable is replaced with the column value for the current iteration. Using this approach, the task can dynamically change for each iteration.
For example, you may have an import that you want to perform for four different entities in your organization. The import configuration is exactly the same except that the source file or query is different for each entity. If the import uses entity as a variable, then you can set up a single import task and configure it to iterate over the list of entities. Each iteration uses a different entity name or code, which you can pass into the import variables so that the import uses the correct source file or query for the current entity.
Enabling iterative processing
Iterative processing is enabled in the Task Control properties of the task. Select the task within the Scheduler job, then click Task Control to expand that section. Any task can use iterative processing, though it is more useful for certain task types such as Import ETL Package.
Complete the following properties in the Iteration section of the Task Control properties.
| Item | Description |
|---|---|
|
Iterate this Task |
Specifies whether iterative processing is enabled for the task. If enabled, then the task will be performed N times, where N is the number of unique items in the specified iteration column. Job variables can be used to apply the current iteration value and iteration number to the task. |
|
Create a Subordinate Job for each iteration |
Specifies whether each iteration is processed as a separate subordinate job. By default, this is disabled, which means that all iterations are processed sequentially within the overall subordinate job created to process the iterations. If enabled, then each iteration is processed as a separate subordinate job, enabling concurrent execution of multiple iterations. This option should only be enabled if the order of iteration processing is not important. |
|
Column |
The column that contains the values to iterate over. Use Table.Column syntax to specify the column. Multiple-level lookups can be used. For example, if you specify |
|
Group By |
Optional. By default, the group by column is the same as the iteration column, so that the task is processed once for each unique value in the iteration column. However, if needed, you can specify a different grouping level. You can use any column or columns that would be valid as the "sum by" level for an Axiom query, where the primary table is the table specified for the iteration column. |
|
Order By |
Optional. By default, the values are sorted based on the iteration column, in ascending order. You can specify a different sort column, or use the same sort column but change the order to descending. The sort order is ascending unless the keyword Dept.Dept desc |
|
Filter |
Optional. A filter criteria statement to limit the list of values for the iterative processing. You can use any filter that is valid against the source table (the table of the iteration column). |
When iterative processing is enabled for a task, the iterations are always processed within a subordinate job. Therefore, enabling the Task Control option of Create a Subordinate Job for this Task is unnecessary.
If your job has multiple tasks, and you want the tasks after the iterative task to wait for all iterations to complete before executing, then you must enable the following Task Control option for the iterative task: Wait for all Subordinate Jobs to complete before proceeding to the next Task.
Configuring the task to change for each iteration
In order for the Scheduler task to apply the current iteration value to each iteration, you must use the built-in iteration variables within the task. These variables are job variables, and can be used like any other job variable. The following variables are available:
| Variable | Description |
|---|---|
|
{Task.CurrentIterationValue} |
Returns the current value from the iteration list. |
|
{Task.IterationNumber} |
Returns the number of the current iteration. |
To continue the previous example, imagine that you are setting up an import for iterative processing by entity. To define the list of entities, you set up the Iteration settings in the Task Control section like the following:
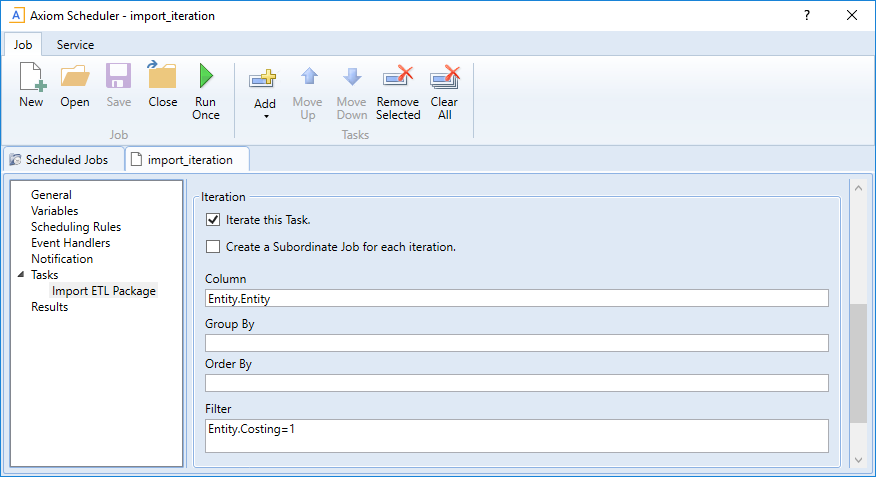
This example will iterate over the list of entities in the Entities column, limited to only those entities where the Costing column is set to True. If this resolves to 4 entities, then the task will be processed 4 times, once for each entity.
The import is configured with a variable {Entity}, which it uses to process the correct entity source file. In order to pass the current task iteration value to the import variable, you can use the job variable {Task.CurrentIterationValue} in the import task settings. For example:
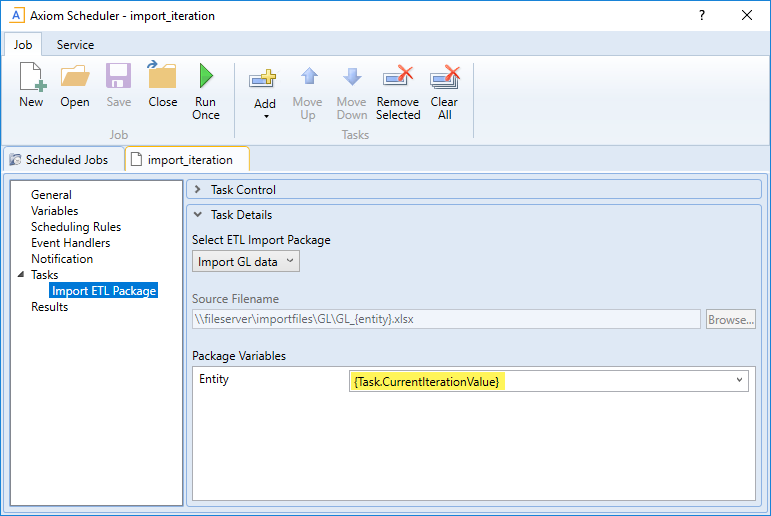
When the first iteration is performed, the {Task.CurrentIterationValue} will be resolved as Entity_1, so the import will be processed using Entity_1 as the value for the {Entity} import variable. For the second iteration, the value Entity_2 will be used, and so on. Using this approach, the import will be processed for all entities in the iteration column.
